Applications for natural language processing frequently employ sizeable pre-trained language models that have been fine-tuned to perform a variety of downstream functions. The original model’s parameters are kept after fine-tuning, which makes deployment difficult for large models like GPT-3, which has 175 billion trainable parameters.
Low-Rank Adaptation, or LoRA, proposes to inject trainable rank decomposition matrices into each layer of the Transformer architecture in addition to freezing the pre-trained model weights, considerably lowering the amount of trainable parameters for downstream tasks.
Before understanding how LoRA achieves this remarkable task of reparameterization of LLMs, let’s understand few key concepts:
- Rank decomposition (or Low Rank Adaptation)
Rank decomposition matrices refer to a technique used to reduce the number of parameters in the model while maintaining its performance.
Let’s take an example of transformer model, the attention mechanism in the Transformer requires the computation of self-attention scores between all pairs of input tokens, resulting in a quadratic complexity with respect to the sequence length.
As a result, the Transformer can become computationally expensive, especially for long sequences.
Instead of using the full self-attention matrix, which is typically of size N x N, where N is the number of tokens in the input sequence, rank decomposition approximates it as the product of three smaller matrices while preserving important information:
Attention_matrix ≈ U x V x W
U: A matrix of size N x r (where r is the rank), representing the “query” matrix.
V: A matrix of size r x N, representing the “key” matrix.
W: A diagonal weight matrix of size N x N, representing the “value” matrix.
The rank r is a hyperparameter that controls the approximation quality. By choosing a smaller rank r compared to the full sequence length N, the number of parameters in the attention mechanism is reduced.
2. Intrinsic Dimensionality
What does intrinsic dimension mean ?
It refers to the number of meaningful features or variables required to describe the data accurately, excluding any irrelevant or redundant information
Surprisingly, a large number of pre-trained models have a relatively low intrinsic dimension, which means that they may be efficiently modified using a small portion of the entire parameter space.
For instance, a RoBERTa model may reach a remarkable 90% of its full parameter performance levels on the MRPC (Microsoft Research Parametric Corpus) by optimising just 200 trainable parameters that are skilfully reprojected into the entire parameter space.
This highlights the potential for efficiency and efficacy when utilising intrinsic dimension in fine-tuning and reaping exceptional benefits with a drastically reduced parameter count.
LoRA Explained
Inspired by this, LoRA goes one step ahead and hypothesize that “Updates to the weights also have a low intrinsic rank during adaptation”
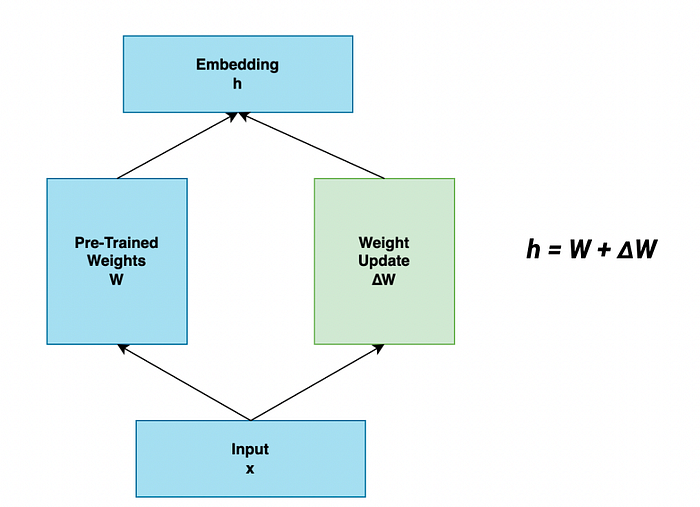
In case of LoRA , for a pre-trained weight matrix W ∈ R d×k , we constrain its update by representing the updated weights (∆W) with a low-rank decomposition W0 + ∆W = W0 + WAWB
where WA ∈ R^d×r , WB ∈ R^r×k , and the rank r min(d, k).
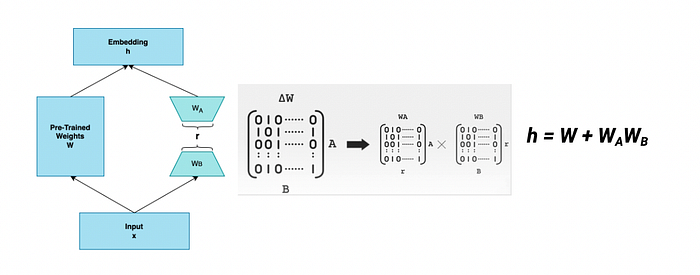
During training, pre-trained weights are frozen and gradient updates are not passed through them, while WA and WB are small dimension matrices that act as an approximation for ∆W.
In simpler terms, these WA and WB matrices hold almost the same information as ∆W.
r here is the hyperparameter, which cannot exceed the smallest dimension in weight matrix W. It decides what should be the rank of these decomposed matrices .
LoRA advantages:
- Shared pre-trained model for multiple tasks, reducing storage and task-switching overhead.
- More efficient training with up to threefold hardware barrier reduction using adaptive optimisers.
- Seamless transition from training to deployment with no inference latency.
- Complements other methods, like prefix-tuning, for enhanced natural language processing possibilities.
LoRA limitation:
LoRA has some limitations due to the loss of information in the low-rank approximation process, which may impact the adapted model’s performance.
The effectiveness of LoRA also relies on the careful selection of decomposition techniques and rank, requiring thorough tuning and experimentation.
Summary:
LoRA is a fine-tuning method that accelerates the training of large models while consuming less memory, by reducing the number of trainable parameters.
For each layer of the LLM, LoRa adds a small number of trainable parameters, or adapters, and freezes all of the original parameters. We simply need to update the adapter weights for fine-tuning, which greatly decreases the memory footprint.
It is a successful adaptation technique that maintains excellent model quality while neither increasing inference delay nor shortening the input sequence.
Citation:
🔗 LoRA Paper: https://arxiv.org/pdf/2106.09685.pdf
🔗 Intrinsic Dimensionality Paper: https://arxiv.org/abs/2012.13255